Library of Congress Digital Preservation using Wikidata URIs!
The Library of Congress Digital Preservation team recently updated their inventory of Format Description Documents to include Wikidata URIs. The Library of Congress has detailed descriptions of more than 400 file formats on their website.
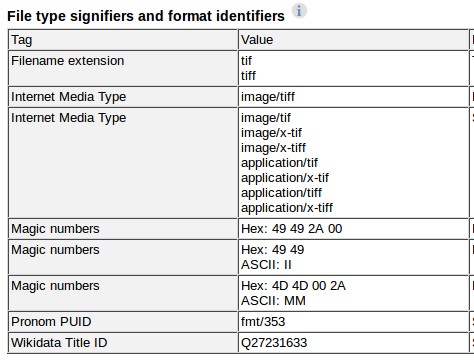
The purposes of these format descriptions are listed on their website:
- To support strategic planning regarding digital content formats, in order to ensure the long-term preservation of digital content by the Library of Congress, and
- To provide an inventory of information about current and emerging formats, including the identification of tools and detailed documentation that are needed to ensure that the Library of Congress can manage content created or received in these formats through the content life cycle, and
- To identify and describe the formats that are promising for long-term sustainability, and develop strategies for sustaining these formats including recommendations pertaining to the tools and documentation needed for their management.
- To identify and describe the formats that are not promising for long-term sustainability, and develop strategies for sustaining the content they contain.
- The overall analysis is part of the execution of the Library of Congress Digital strategic plannning goal pertaining to the management and sustenance of digital content.
I’m looking forward to seeing many additional cultural heritage institutions and organizations using Wikidata URIs in the future.
Wikidata is already serving as a crosswalk between identifiers. Here is a SPARQL query for the Wikidata endpoint showing all of the items in Wikidata for which we have IDs from the Library of Congress, PRONOM, and the Just Solve Wiki.
UPDATE: I updated this post on March 15, 2017 with new links to the Library of Congress websites.