The short version:
You can validate your EAD files in bulk before importing them into ArchivesSpace. Essentially, there’s an easy way to do this and a hard way. The easy way requires that you have the oXygen XML Editor. With that, just add as many EAD files you want to an oXygen project and then validate them all in one step. I’m not going to give detailed instructions on how to do batch validation without oXygen in this blog post, which is more difficult to set up, but I will give you a general sense of how it works and point you in the right direction. Also, I’ll try to explain why you should be interested in validating your files in bulk prior to importing anything (EAD, MARC, whatever) into ArchivesSpace.
So on to the longer version:
If you’ve ever attempted to import EAD files into ArchivesSpace, you might have encountered some rather cryptic errors. Here’s one:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
IMPORT ERROR
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
The following errors were found:
dates : one or more required (or enter a Title)
title : must not be an empty string (or enter a Date)
For JSONModel(:archival_object):
#<JSONModel(:archival_object) {"jsonmodel_type"=>"archival_object", "external_ids"=>[], "subjects"=>[], "linked_events"=>[], "extents"=>[], "dates"=>[], "external_documents"=>[], "rights_statements"=>[], "linked_agents"=>[], "restrictions_apply"=>false, "instances"=>[], "notes"=>[], "uri"=>"/repositories/import/archival_objects/import_ac6a66e9-fc60-4565-a6ec-50b9895b6783", "level"=>"file", "ref_id"=>"mferd61e7996", "resource"=>{"ref"=>"/repositories/import/resources/import_8799af4a-30e8-4f48-8822-56132f31b4c2"}, "parent"=>{"ref"=>"/repositories/import/archival_objects/import_e3f5613a-5df5-4999-848c-e80a874d8ea0"}, "publish"=>true, "component_id"=>""}>
In :
<c04 class="cdata" id="mferd61e7996" level="file"> ... </c04>
The reason that these error messages might seem unhelpful to you is because the ArchivesSpace EAD importer converts and breaks down your EAD file into a series of JSON objects. These JSON objects are then validated by the ArchivesSpace data model before updating the database. If one of these JSON objects proves invalid, then the entire import process for an EAD file will fail. One issue with this behavior is that when the error is registered, the ArchivesSpace importer no longer has any connection to the original EAD file; consequently you see error messages that don’t tell you exactly where in the file the error occurs (that is, you don’t get a line number, file name, etc.). And those errors can be pretty difficult to hunt down. Actually, the error reporting has improved significantly in the current version of ArchivesSpace, since I’m now given that last bit of text after the “In” header. There, I get some escaped XML tags that clue me in where to look. In this case, there’s a distinct ID on the element and I could search for that ID in the file by looking for “mferd61e7996”. But that’s still a lot of work for just one error in a single file, and if the file didn’t have IDs for each and every component, the error would be even harder to track down. So, there has to be a better way to do this, especially if you need to batch import files, and luckily there is.
But first, there are two things that you need to understand about the ArchivesSpace data model:
- The ArchivesSpace data model supports only a subset of the EAD 2002 schema.
- In some cases, the ArchivesSpace data model is stricter than the EAD 2002 schema.
Because of thing one, you have to get used to the fact that you can no longer have things like nested control access sections if you adopt ArchivesSpace. This is not bad EAD, in my opinion, it’s just something that ArchivesSpace does not support, just like how the Archivists’ Toolkit does not support it, or any other archives management tool that I know of (aside from EADitor, I imagine).
Because of thing two, you might reasonably wonder why you get errors when trying to import perfectly-valid EAD files into ArchivesSpace. This is actually a really good thing in a lot of ways, but it can be frustrating. For example, this is perfectly valid encoding in EAD 2002:
<unitdate normal="1887/1797"/>
This is clearly a typo in the encoding, though, since the normalized ISO 8601 end date should never occur before the begin date. The encoding for this component should actually be:
<unitdate normal="1887/1897"/>
Fortunately this type of error is something that will be ferreted out when importing EAD into ArchivesSpace. Since the EAD 2002 schema won’t catch it, though, we need to use something else to ensure that the EAD adheres to the ArchivesSpace data model, and that’s where the following Schematron file comes into the picture: https://raw.githubusercontent.com/fordmadox/schematrons/master/ArchivesSpace-EAD-validator.sch
Schematron is another way to validate XML files, and this particular Schematron file is an early attempt at expressing where the ArchivesSpace data model is stricter than the EAD 2002 schema in order to help improve the EAD import process. It is by no means comprehensive at this point, but I’ve certainly found it extremely helpful when running some of my own tests.
Okay, so let’s say that you’re tasked with importing 5,000 EAD finding aids into ArchivesSpace. Or, even if you have just 10 files to upload, do you really want to find out about any incompatibilities with the ArchivesSpace data model on a case-by-case basis? If not, it’s time to batch validate your EAD files.
Here are two ways to batch validate your files:
- Use oXygen! This is by far the easiest method. It’s not free, but you can still get a lot of files validated in batch during the 30-day trial period. After that, you’ll probably find that it’s an extremely worthwhile purchase. To validate in batch, you should start by creating a new project in oXygen. I’ll name my project aspace-batch-import.xpr. To add files, just right click on the project name and select “add folder” or “add files.” After you’ve done that, select the directories or files that you want to validate, right click, and then chose any one of the four validation options to get started. Here’s what that will look like:
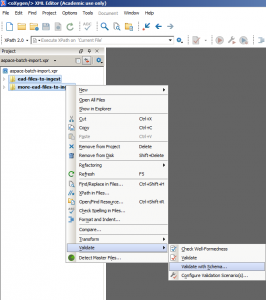
In this example, I’m validating two directories of EAD files at once. One directory has 138 EAD files, and the other contains 1,337 files. I really don’t want to import these 1,475 EAD files and fix them one at a time, so once I run a single validation step on these files, oXygen very nicely packages up a set of results for me. In this case, I have 144,144 errors to address, so clearly I have my work cut out for me! In actuality, though, most of these errors are really simple to address in bulk (almost all of these errors, in fact, are letting me know that most of these archival components don’t have an EAD level attribute assigned).
Let’s take a look at just a single file. When oXygen reports its errors, it will tell you four really important things: the EAD filename, the validation filename that raised the error, a description of the error that is produced by the validation file, and the location of the error within the EAD file. Here’s what that information looks like in the interface:

Even better, if I double click on that first result, which tells me that this particular archival component is missing a title or a date, then oXygen will open that EAD file and take me directly to the error:
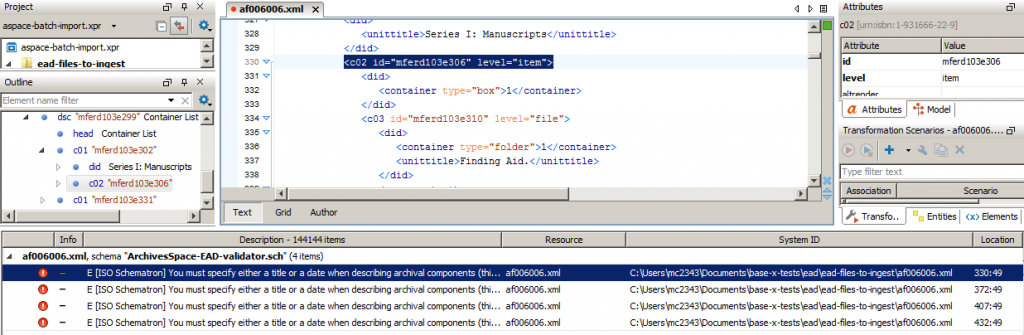
And that’s pretty handy!
- Script your own solution, which you can run from the command line. In this case, you’ll need to have your own XSLT processor, like Saxon 9. I won’t get into all of the details here, but suffice it to say that Schematron is essentially a validation process that uses a series of transformation steps to perform validation. Therefore, if you can run batch XSLT transformations on the command line, you can do the same with batch validations. Just check out the Schematron website for more details, as well as all of the required XSLT files that you’ll need: http://www.schematron.com/implementation.html



Lastly, you don’t have to limit yourself to just one validation step at a time if you’re running things in batch, whether in oXygen or elsewhere. If you have EAD 2002 files, for instance, your first step should be validating those files against the EAD 2002 schema or the DTD. After that, you could validate your files against this Schematron file or any other validation files — for example, you might want to enforce additional rules on your own files based on local best practices. You can even do more than that, if you’d like, by including progressive validation steps, automatically updating files based on the errors, etcetera. It’s really powerful stuff!
If you haven’t done bulk validations before, you should try it out since it’s one of the easiest ways to verify that your files will import into ArchivesSpace without going the trial-and-error route, which is incredibly inefficient and frustrating.
I hope this helps!