On the week of January 29 Stanford hosted geo4libcamp where 48 people of similar but varying persuasions convened with the common goal of building repository services for geospatial data. Introductions included naming 3 personal interests and “discovery”, “metadata” were among the most frequently cited. The format was of “unconference” design Monday through Wednesday with additional sessions Thursday and Friday. There were 6 planned presentations, a round of lightning talks, a morning spent at the Rumsey Map Center, and unconference planning that determined the 10 unconference sessions chosen by popular demand. Additional sessions included an introduction and tutorial on Geoblacklight, hydra plugin development, and selling the importance of geodata repository to administrators. For more details of the week see: https://geo4libcamp2017.sched.com.
Geoblacklight is an open source GIS discovery platform for geospatial holdings built on the blacklight discovery application and solr index. At Yale, the Library Executive Committee has made creating a Geoblacklight instance a high priority and it was assuring to see that the community is moving with concerted effort in that direction. Highlighted throughout the week were the common challenges, from technically standing up the software stack, metadata best practices, sharing and interoperability, to specific issues with scanned maps, indexed maps, and hierarchical data. One key takeaway was the compelling argument to adopt geoconcerns: It leverages the existing hydra/sufia/hyrax model, there was a critical mass of buy-in and support, the data model is robust, and the infrastructure and architecture are well defined. Through contributing to the community effort and custom development at Yale with the Ladybird collection management tool and existing metadata, a geoblacklight/geoconcerns solution holds much promise as a leading application to offer Yale patrons in the geospatial realm.
In October we completed the ingest of digitized materials for the Henry Kissinger project into Hydra and as a result, checked off a major milestone for the project. Ingest began in September 2014 and overall took 249 days to complete where for many weeks the ingest process was running 24/7 and required close monitoring.
The ingest process involved first creating metadata records in Ladybird from the original EAD files for the Kissinger collection (MS 1981 and MS 2004). This amounted to 16,161 Ladybird objects. Then as each of the 85 hard drives returned from the vendor, each drive had its contents validated through an automated quality control process and then transferred to temporary, network accessible storage for a manual quality control process. Once the digital files passed the quality control phase, they were matched up with the Ladybird object to create the complex parent/child relationship, essentially combining the metadata record with the digital files. This was performed by using the file name from each TIF image and extracting parts of the name to match it to the Ladybird record. Once a match was made, we imported the TIF and associated OCR file into Ladybird to create the ingest package to send to Hydra. Each ingest package contained the original TIF image, OCR file, a derivative JP2 and a derivative JPG. In addition, five metadata files were also attached which make up the Hydra object.
After completing ingest into Hydra, we then performed two independent audits to confirm the quantities of files matched correctly and each file’s checksum matched the original checksum in addition to the checksums calculated along the way to ensure file integrity.
Combining the counts of files for both MS 1981 and MS 2004, this is the end result:
Total Folders
16,161
Folders with digitized content
15,710
PDF files
15,710
Folders containing Audio/Video
157
Total TIF Images
1,530,433
Total OCR Files
1,202,920
Total Ladybird objects
1,546,594
Total Files Ingested into Hydra
13,542,899
Approximate checksums calculated
39,268,398
Estimated size of collection
95 Terabytes
The following chart illustrates the growth by month from September 2014 through October 2015.
The HydraConnect 2015 conference took place September 21-25 in Minneapolis[1] totaling 200 people from 60 institutions including 2 representatives from Yale, Kalee Sprague and Eric James. The conference was structured with Monday Workshops, a Tuesday morning plenary, a Tuesday afternoon poster session, and sessions, lighting talks, and breakout groups on Thursday and Friday. The project “Hydra” has come to represent an aggregation of components serving the needs of the digital community. Core applications include Blacklight[2] – a discovery index and interface, Sufia[3] – an institutional repository supporting self-upload, Avalon[4] – an application for audio/video materials, Spotlight[5] – an exhibit creation tool, Stanford Earthworks[6] – supporting spatial discovery, and Hydra in a Box[7] – a new project to create a turnkey Hydra application. The main themes of the conference were linked data and interoperability, the approach of defining a content model by fleshing out metadata concerns driven by end user requirements. To this end several initiatives are currently under development centered around The Portland Common Data Model PCDM[8], a construct built on the resource/description/containment spec of the Linked Data Platform[9], providing a generic framework for resource properties and association. A key component of this is the championing of the approach of using dereferenceable URIs[10] in metadata description and tackling the challenges this entails such as enriching current literal description, resolving URIs to its constituent properties, caching fragments of this linked data, and achieving all of this in a platform agnostic way. Complementing this work are several interest and working groups, addressing the specific areas such descriptive/rights/structural metadata, service management, UX design, and archival interests. HydraConnect 2015 is the third conference of its kind and has grown considerably each year with expectations of much development to continue.
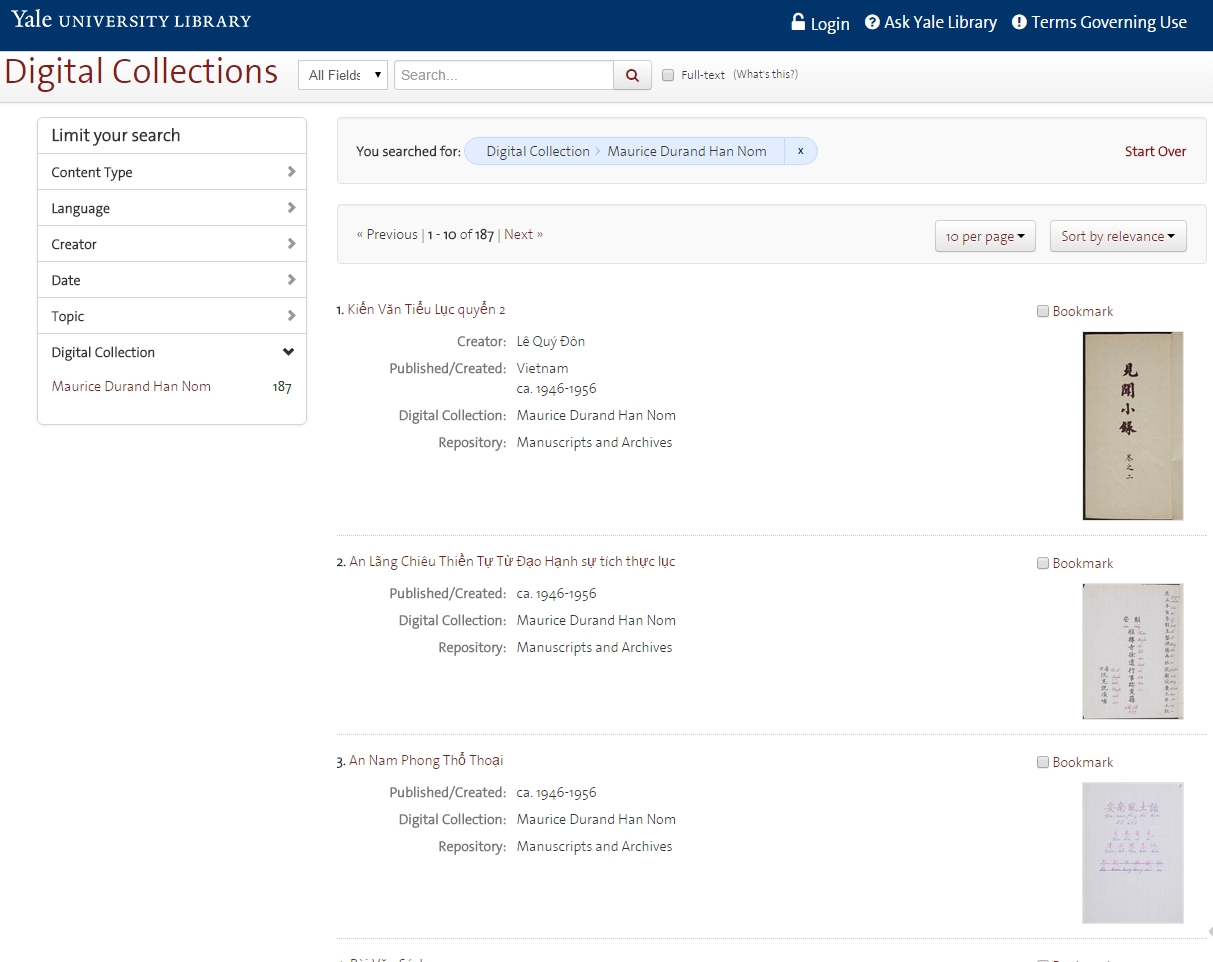
On Monday 9/21/2015, YUL’s digital collection discovery interface (findit.library.yale.edu) will go live with a new design modeled on the Quicksearch interface design. These coordinating designs let our users know that they are in the same Yale University Library web space and should expect similar functionality.
The new look and feel of digital collections search at YUL- main page (click the image to get a larger view):
Search results in the new design:
There will also be a few new features in the digital collections search added on Monday. These include:
an Access Restrictions facet, to limit by either open or restricted access
a Repository facet, to limit to and search within a specific repository at YUL
a Call Number facet, to limit to and search within call numbers assigned to items
Another feature coming soon (but not on Monday) is a date slider with a histogram visualization, which gives users the ability to limit by date range and see the frequency of hits in a given year. To see an example of a feature like this used elsewhere, click on this search of Articles+ and look to the lower left to see the date range and histogram.
As always, your feedback is welcomed and appreciated. Please use the feedback link on the bottom center of the digital collections search page (or just click here), and tell us your thoughts!
Central ITS will be conducting the first of three load tests on the enhanced interface for digital collections on Friday July 17th between 1:30pm and 5pm. They will use a service called LoadRunner which determines the breaking point of an application by emulating real use by a number of concurrent users. The second two tests will take place between July 27 and July 30. I will follow up once these dates and times are confirmed.
These tests on the enhanced interface for digital collections are not expected to impact the current digital collections interface. Library IT will be monitoring the current digital collections interface on 7/17 for service disruptions.
I write to you regarding some testing on the enhanced interface for digital collections that mayimpact our current digital collections discovery service (http://findit.library.yale.edu). The enhanced interface for digital collections is a version of this digital collections discovery service, with features, functionality and security developed for use with more restricted digital materials. Like our unified discovery service,Quicksearch, both the digital collections interface and the enhanced version are powered by Blacklight.
Curious about what’s in the Yale University Library digital collections search? Here’s some clocks made by Paul Revere. We also have fire insurance maps of Seymour, CT– and much more! You can learn more about the Library’s discovery services (Articles+, Quicksearch and digital collections search) at the Rediscover Discovery forum in August (Tues 18th and Thurs 20th). More information on that coming soon.
Library IT’s CTO Michael Dula presented on digital repository development last week at the Coalition for Networked Information’s fall 2014 meeting in Washington D.C. The presentation is linked here.
via CNI.org: The Coalition for Networked Information (CNI) is dedicated to supporting the transformative promise of digital information technology for the advancement of scholarly communication and the enrichment of intellectual productivity. Some 220 institutions representing higher education, publishing, information technology, scholarly and professional organizations, foundations, and libraries and library organizations make up CNI’s members; CNI is entirely funded through membership dues. Semi-annual membership meetings bring together representatives of CNI’s constituencies to discuss ongoing and new projects, and to plan for future initiatives.
Quicksearch beta, a Blacklight-powered library search of the Orbis and Morris catalogs, along with Articles+ from Summon, has been available for library-staff testing since October 2014. Recently staff from around the library conducted usability tests of Quicksearch beta with 14 students. Tests took about half an hour to complete, and consisted of a set of typical library search tasks such as finding a book by title and author, looking for a journal, finding books and articles in a topic, and saving/requesting and citing material. Teams of library staff worked on tests, with one person recruiting testers, a second asking the questions and running the tests, and a third person recording the sessions. Test takers were asked to think aloud during testing and their comments and actions were written down by the observer staff person. These types of “think aloud protocol” usability tests are considered an inexpensive and reliable way to uncover problems with digital interfaces, and are conducted as standard parts of interface development cycles.
Usability testing was done in large part to determine if Quicksearch beta is ready for wider release to Yale students and faculty in the spring semester. During testing the only problem uncovered which must be addressed before Quicksearch beta can be more widely disseminated to the Yale community was that response time slowed considerably, to a level which is not acceptable in a search interface. Modern expectations of search is that results will be returned within one second on average. Anything longer than two or three seconds causes users to question if an interface is working. LIT staff are now working to address the slow response times. Culprits may include the SOLR index used in Quicksearch beta, the Blacklight application, the hardware environment, or a combination of these three things. This complexity makes troubleshooting a challenge.
Quicksearch beta includes results from books and articles, which are presented side-by-side in one screen. Labeling in this display was problematic for test takers. The use of Catalogs (to represent material from the Orbis and Morris catalogs) did not seem to mean much to test takers. We recommend that Catalogs be replaced by Books+ to make the material found in Catalogs clearer and to draw a more obvious distinction with Articles. We also recommend changing Articles to Articles+, and to be consistent with this wording throughout the search application.
Side-by-side display of results from catalogs and Summon (Articles+) in the Quicksearch beta display.
Test takers had some trouble with complexity of moving between areas for books and articles, and understanding when books were being searched, when articles were being searched, and when both types of materials were being searched. Visual cues need to be added to the books only and articles only areas so that that the material searched there is more obvious.
Lack of obvious visual cues on the page and the search box made it difficult for test takers to understand the context of search.
One task for which Quicksearch was not successful for most users was finding a recent issue of a journal. The search did not do a good job bringing a journal title to the top of search results. The SOLR index and relevancy ranking can be manipulated to make this type of search function better, or other targeted ways of doing a journal title search need to be added to the Quicksearch beta interface.
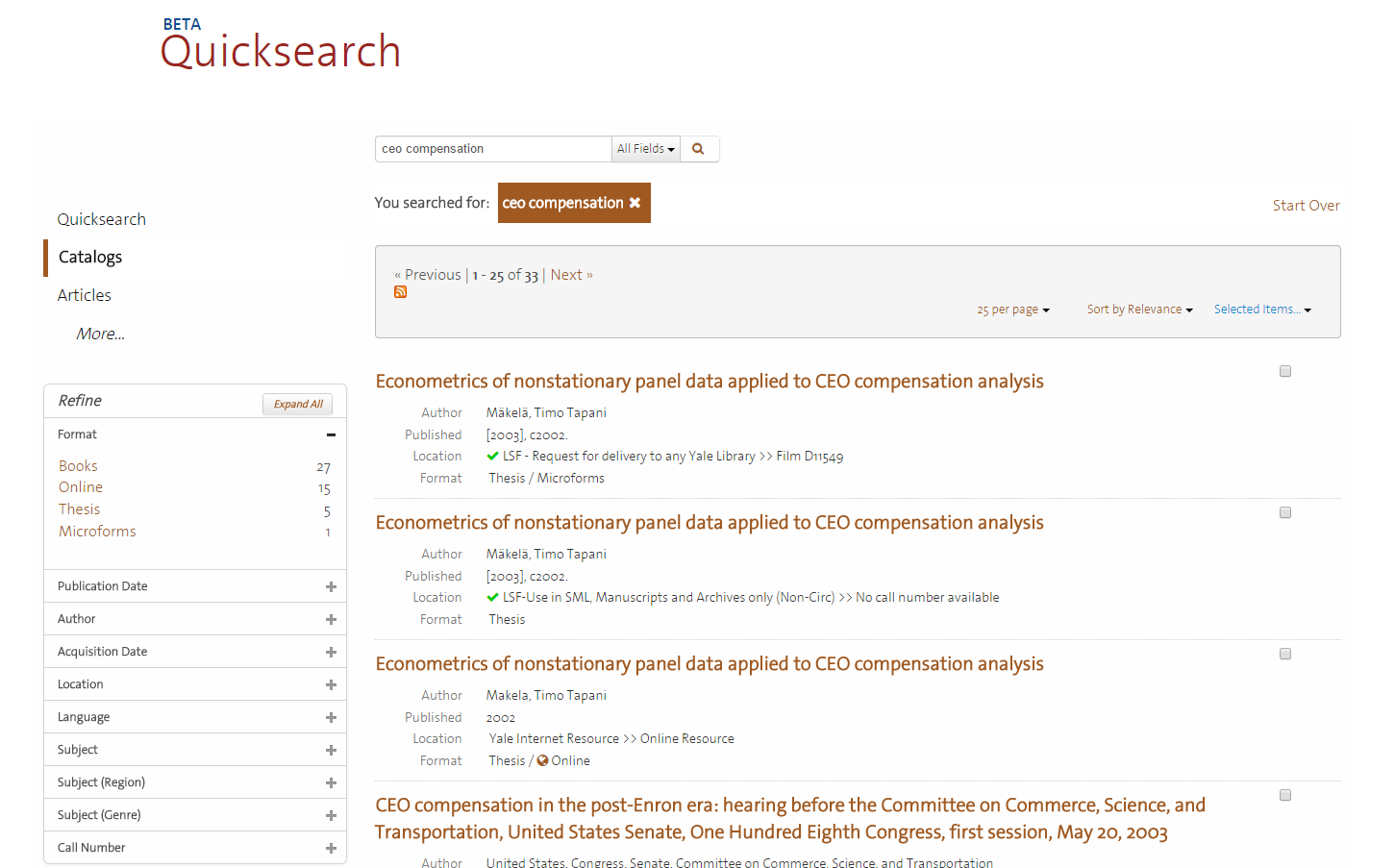
Another problem was seen when users were asked to limit a set of book results to a more targeted set of books in a subtopic (in this case, books that were about the law or legal aspects of a subject such as CEO compensation, Ebola, or climate change). The Quicksearch beta interface should make such a task straightforward, or at least that the hope, through the use of subject facets. Most users could not, however, complete this task using subject facets. There was a greater rate of success (73% success versus 46% success) when users were asked to do a similar narrowing of results of articles. Users are presented with different sets of facets for books and articles, and there are actually less facets available for articles. It could be that the simpler list of facets makes the topic facet more easy to spot and use in article search results.
Other aspects of Quicksearch beta worked very well and caused few problems for most users. All test takers were able to successfully find a book by a known title, identify where it was in the library system, and navigate to the order form. Most test takers were also able to save article records for later use and email citations.
Probably the biggest win from Quicksearch beta is just the simple fact of the single search of Orbis and Morris in one interface. There was not a lot of name recognition of Orbis demonstrated by these students and even less of Morris. The chance of a student searching one of these resources seems to be decreasing over time, the chance of searching both of them for material seems unrealistic. Quicksearch beta successfully combines both resources in one search, thereby saving time for Yale users and potentially surfacing far more library material in the process.
A small group met this week consisting of Public Services staff and Library IT staff to identify the high priority issues that need to be resolved before we can release Quicksearch Beta for evaluation by students and faculty.
It was generally agreed that we need to put the word ‘Beta’ in as many places as possible, so it’s clear to users that this is a very early version of the interface, and not a finished product.
The specific issues that were identified as requirements for the soft rollout included:
Addressing the insertion of the phrase ‘|DELIM|’ between subfields in the uniform title (240) field display
The Articles+ lack of a pre-limit to Yale-only materials
The sublineal dot is appearing as a box in some instances – this might affect French, Turkish, South East Asian languages, and more
Item Status isn’t accurate, esp. for Patron status messages – items with a status ‘on Arts New Book Shelf’ display as ‘Unavailable’
Link directly to the current record in Morris from the item detail page, instead of going to the Morris home page
These are our priorities for the next two weeks. Right now our goal is to resolve these issues and do a soft release of Quicksearch Beta the first week in November.
Many thanks to everyone who has provided feedback about the Quicksearch Beta interface!
Our favorite feedback message so far:
“YAY QUICKSEARCH BETA! I just ran my old faithful search, “water nepal” and got some slammin results.”
We’ve also received a lot of great suggestions for changes that would make the interface work better. For example, two staff members suggested linking to the Orbis record, instead of directly into the Orbis Request feature, so that our patrons can access all of our Scan and Deliver, Aeon, and other request options.
That’s just the sort of feedback we’re looking for!
We have already started work reviewing and making changes like this where we can. You can see the full list of issues reported and new features requested online on our two sharepoint lists:
We hope you will continue exploring Quicksearch Beta (http://search.library.yale.edu) , particularly by using it as part of your daily work. Please report any comments or suggestions you may have via the ‘Feedback’ links in the header and footer of each Quicksearch page.